I am Enrico Pesce and I publish practical guides on Oracle Cloud Infrastructure, OCI Generative AI, OKE/Kubernetes, serverless architecture, automation, and cloud benchmarks. This site collects technical examples, benchmarks, and open-source projects for people working with OCI.
Protect Oracle Database with Continuous Backup, Wherever It Runs
An Oracle database can run on premises, with another cloud provider, or in OCI. The question does not change: how much data can we afford to lose in the event of ransomware, an application error, logical corruption, or an infrastructure failure? With Oracle Zero Data Loss Autonomous Recovery Service and Cloud Protect, you can centralize database protection in Oracle Cloud Infrastructure while applications and operational data remain in their current location. ...

Reduce Linux RAM Usage: A Practical Plan and Final Benchmark
If you search “reduce Linux RAM usage”, what you mostly find is lists of sysctls to paste — set swappiness to this, drop the caches, disable that. I’ve never seen that approach survive contact with a real production host. What works is much less glamorous: a measure-change-verify cycle, applied in the right order — shrink the application working set first, isolate services second, compress third, and buy RAM only when the numbers prove nothing else will do. ...

Limit Linux Service RAM with systemd and cgroup v2
Everyone who has run Linux servers for a while has lived through some version of this incident: one service — a leaky app, a batch job, a runaway query — grows until the whole host starts thrashing, and by the time the OOM killer wakes up, it kills something you cared about more than the actual culprit. The zram and zswap work from part 2 protects you from peaks, but it does nothing against this. Compression buys headroom; it doesn’t assign blame. ...

Zram, zswap and Linux Swap: A Practical Configuration Guide
In part 1 of this series I made the case for measuring memory pressure before spending money on RAM that now costs more than four times what it did a year ago. If your measurements showed short, compressible peaks — cold pages sitting around while the active working set fits fine — this is the post where compression earns its keep. I want to be upfront about one thing, because “just enable zram” has become the reflexive advice in every forum thread about low memory: zram and zswap do not create free memory. They spend CPU cycles compressing pages you are not actively using. When the data compresses well and the CPU has headroom, that trade is excellent. When it doesn’t, you’ve added a layer of complexity and gained nothing. So the goal here is not to enable everything — it’s to pick one mechanism deliberately and prove it helps. ...

Record RAM Prices: Measure Linux Memory Before Buying More
The first time I priced out a memory upgrade this year, I assumed the listing was wrong. It wasn’t. DRAM contract prices are now more than four times what they were in the third quarter of 2025, and suddenly a question that used to be a no-brainer — “should I just add RAM?” — is worth actual engineering time again. That’s what this series is about. For years, throwing memory at the problem was the rational move: RAM was cheap, engineer hours weren’t. In 2026 that math has flipped, and before spending money at these prices you want to know whether the constraint is real memory pressure, reclaimable cache that only looks like consumption, or one process that nobody has looked at in months. This first part builds that answer — a reliable baseline. Part 2 configures swap, zram and zswap , part 3 contains services with cgroups , and part 4 puts it all together into a plan and a buy-or-optimize decision . ...

OCI Generative AI in Python: Where to Start
Every time I start experimenting with a new framework or API style on OCI Generative AI, I waste the same hour rebuilding the same boilerplate: right credentials, right endpoint, right model ID format, right environment variables. Then I discover that LangChain and the OpenAI-compatible API use a different variable than the raw SDK. Then I find that the newer Responses API needs a project OCID that the chat completions endpoint does not. ...

OCI E6 vs E5 vs E4: Compute Flex Shapes
In brief OCI E6 Standard Compute is the next AMD x86 generation to evaluate when you are choosing between VM.Standard.E6.Flex, VM.Standard.E5.Flex, and VM.Standard.E4.Flex. If you are starting a new OCI workload today, E6 should be on the shortlist before E5 or E4. The reason is simple: Oracle positions E6 as a newer 5th Gen AMD EPYC-based generation with better performance at the same price point as E5 in its launch messaging. That does not make old benchmarks useless, but it changes the next decision: every existing E5/E4 benchmark should now have an E6 follow-up. ...
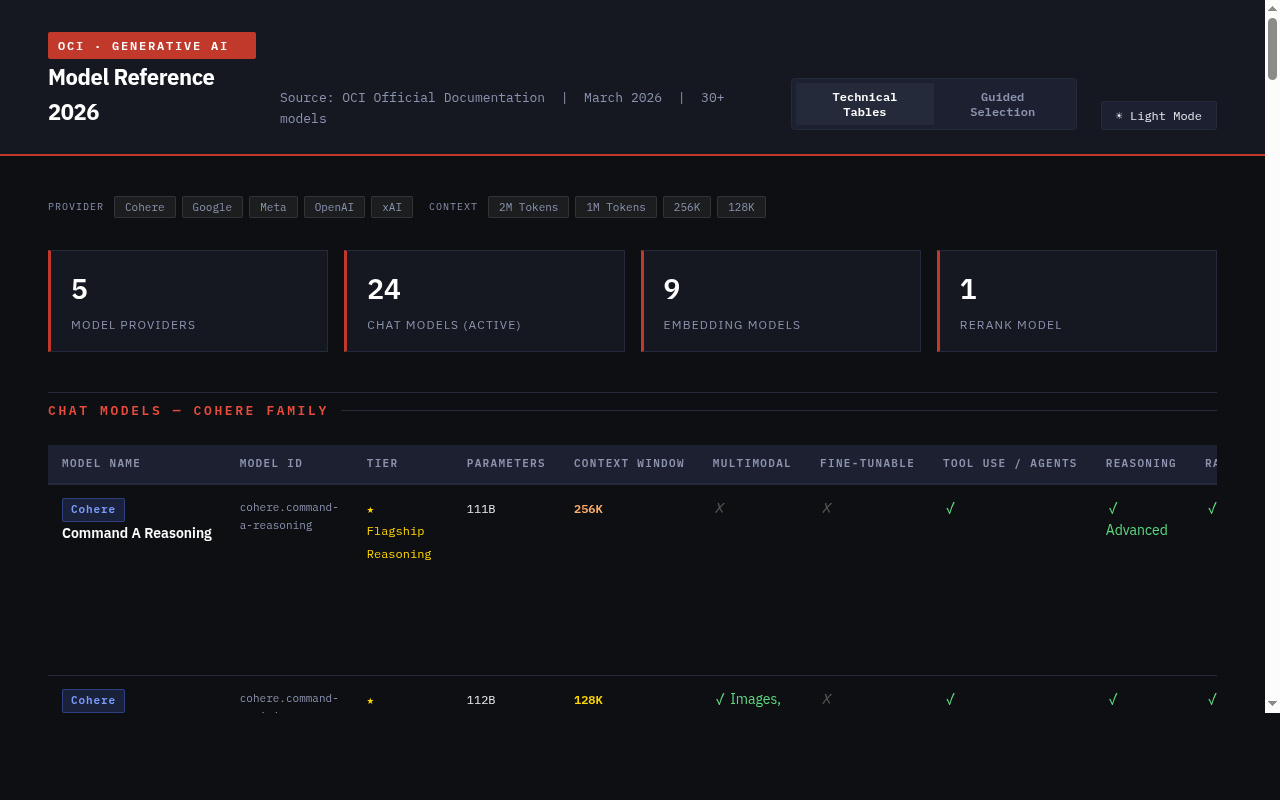
OCI GenAI Catalog: Pick the Right Model
OCI Generative AI has grown fast—Cohere, Google, Meta, OpenAI, xAI—all available, each with multiple variants. Every time I started a new project I had to dig through documentation to find the right model. So I built OCI GenAI Catalog : a reference guide covering 30+ models with a guided selection wizard. What’s inside 24 chat models from 5 providers, with specs: context window, multimodal, tool use, reasoning, fine-tuning support 9 embedding models and 1 reranking model for RAG pipelines A model selection wizard — filter by task, performance tier, and context needs to get a top-3 recommendation Provider summary Provider Models Strength Cohere 5 RAG, fine-tuning Google Gemini 3 Multimodal, long context (up to 1M tokens) Meta Llama 5 Open weights, MoE efficiency OpenAI gpt-oss 2 Reasoning, agents xAI Grok 6 2M context, code specialization Data is sourced from OCI official docs and kept up to date. Check it out at OCI GenAI Catalog .

Generative AI: Efficient Inference on Cloud CPUs
It’s been a while since I last wrote here. Lately, I’ve been diving deep into AI inference—the process of running AI models to generate responses—specifically exploring whether we truly need expensive GPUs for running modern language models. Spoiler alert: the answer might surprise you. After extensive testing on Oracle Cloud Infrastructure (OCI), comparing ARM-based Ampere processors against the latest AMD EPYC chips, I discovered that the right combination of software optimizations and compressed models can deliver remarkable performance—all without a single GPU. ...
Deploy Oracle Kubernetes Engine Clusters in Minutes
In today’s cloud-native landscape, Kubernetes has become the de facto standard for container orchestration. However, setting up a production-ready Kubernetes cluster can still be a complex and time-consuming process, especially for those new to the ecosystem. Enter OKED (Oracle Kubernetes Engine Deploy), an elegant solution that streamlines the deployment of Kubernetes clusters on Oracle Cloud Infrastructure. What is OKED? OKED is an automated tool that simplifies the deployment of Oracle Kubernetes Engine (OKE) clusters. Built on the Pulumi framework, it enables users to have a fully functional Kubernetes environment up and running in minutes—without requiring extensive expertise in either OCI or Kubernetes. ...